
pyhrf.jde.jde_multi_sujets.BOLDGibbs_Multi_SubjSampler(nb_iterations=3000, obs_hist_pace=-1.0, glob_obs_hist_pace=-1, smpl_hist_pace=-1.0, burnin=0.3, callback=<pyhrf.jde.samplerbase.GSDefaultCallbackHandler object>, response_levels=<pyhrf.jde.jde_multi_sujets.NRLs_Sampler object>, noise_var=<pyhrf.jde.jde_multi_sujets.NoiseVariance_Drift_MultiSubj_Sampler instance>, hrf_subj=<pyhrf.jde.jde_multi_sujets.HRF_Sampler instance>, hrf_var_subj=<pyhrf.jde.jde_multi_sujets.HRFVarianceSubjectSampler instance>, hrf_group=<pyhrf.jde.jde_multi_sujets.HRF_Group_Sampler instance>, hrf_var_group=<pyhrf.jde.jde_multi_sujets.RHGroupSampler instance>, mixt_params=<pyhrf.jde.jde_multi_sujets.MixtureParamsSampler instance>, labels=<pyhrf.jde.jde_multi_sujets.LabelSampler instance>, drift=<pyhrf.jde.jde_multi_sujets.Drift_MultiSubj_Sampler instance>, drift_var=<pyhrf.jde.jde_multi_sujets.ETASampler_MultiSubj instance>, stop_crit_threshold=-1, stop_crit_from_start=False, check_final_value=None)¶Bases: pyhrf.xmlio.Initable, pyhrf.jde.samplerbase.GibbsSampler
cleanObservables()¶computeFit()¶computePMStimInducedSignal()¶compute_crit_diff(old_vals, means=None)¶default_nb_its = 3000¶finalizeSampling()¶getGlobalOutputs()¶initGlobalObservables()¶inputClass¶alias of BOLDSampler_MultiSujInput
parametersComments = {'obs_hist_pace': 'See comment for samplesHistoryPaceSave.', 'smpl_hist_pace': 'To save the samples at each iteration\nIf x<0: no save\n If 0<x<1: define the fraction of iterations for which samples are saved\nIf x>=1: define the step in iterations number between backup copies.\nIf x=1: save samples at each iteration.'}¶parametersToShow = ['nb_iterations', 'response_levels', 'hrf_subj', 'hrf_var_subj', 'hrf_group', 'hrf_var_group']¶saveGlobalObservables(it)¶stop_criterion(it)¶updateGlobalObservables()¶pyhrf.jde.jde_multi_sujets.BOLDSampler_MultiSujInput(GroupData, dt, typeLFD, paramLFD, hrfZc, hrfDuration)¶Class holding data needed by the sampler : BOLD time courses for each voxel, onsets and voxel topology. It also perform some precalculation such as the convolution matrix based on the onsests (L{stackX}) —- Multi-subjects version (cf. merge_fmri_subjects in core.py)
buildCosMat(paramLFD, ny)¶buildOtherMatX()¶buildParadigmConvolMatrix(zc, estimDuration, availableDataIndex, parData)¶buildPolyMat(paramLFD, n)¶calcDt(dtMin)¶chewUpOnsets(dt, hrfZc, hrfDuration)¶cleanMem()¶makePrecalculations()¶setLFDMat(paramLFD, typeLFD)¶Build the low frequency basis from polynomial basis functions.
pyhrf.jde.jde_multi_sujets.Drift_MultiSubj_Sampler(val_ini=None, do_sampling=True, use_true_value=False)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
Gibbs sampler of the parameters modelling the low frequency drift in the fMRI time course, in the case of white noise.
checkAndSetInitValue(variables)¶getOutputs()¶get_accuracy(abs_error, rel_error, fv, tv, atol, rtol)¶get_final_value()¶get_true_value()¶linkToData(dataInput)¶sampleNextAlt(variables)¶sampleNextInternal(variables)¶updateNorm()¶pyhrf.jde.jde_multi_sujets.ETASampler_MultiSubj(val_ini=None, do_sampling=True, use_true_value=False)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
Gibbs sampler of the variance of the Inverse Gamma prior used to regularise the estimation of the low frequency drift embedded in the fMRI time course
checkAndSetInitValue(variables)¶linkToData(dataInput)¶sampleNextInternal(variables)¶pyhrf.jde.jde_multi_sujets.HRFVarianceSubjectSampler(val_ini=array([ 0.15]), do_sampling=True, use_true_value=False, prior_mean=0.001, prior_var=10.0)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
#TODO : comment
checkAndSetInitValue(variables)¶getOutputs()¶linkToData(dataInput)¶sampleNextInternal(variables)¶pyhrf.jde.jde_multi_sujets.HRF_Group_Sampler(val_ini=None, do_sampling=True, use_true_value=False, duration=25.0, zero_contraint=True, normalise=1.0, deriv_order=2, covar_hack=False, prior_type='voxelwiseIID', regularise=True, only_hrf_subj=False, compute_ah_online=False)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
HRF sampler for multisubjects model
P_COMPUTE_AH_ONLINE = 'compute_ah_online'¶P_COVAR_HACK = 'hackCovarApost'¶P_DERIV_ORDER = 'derivOrder'¶P_DURATION = 'duration'¶P_NORMALISE = 'normalise'¶P_OUTPUT_PMHRF = 'writeHrfOutput'¶P_PRIOR_TYPE = 'priorType'¶P_REGULARIZE = 'regularize_hrf'¶P_SAMPLE_FLAG = 'sampleFlag'¶P_USE_TRUE_VALUE = 'useTrueValue'¶P_VAL_INI = 'initialValue'¶P_VOXELWISE_OUTPUTS = 'voxelwiseOutputs'¶P_ZERO_CONSTR = 'zeroConstraint'¶checkAndSetInitValue(variables)¶defaultParameters = {'compute_ah_online': False, 'derivOrder': 2, 'duration': 25, 'hackCovarApost': False, 'initialValue': None, 'normalise': 1.0, 'priorType': 'voxelwiseIID', 'regularize_hrf': True, 'sampleFlag': True, 'useTrueValue': False, 'voxelwiseOutputs': False, 'writeHrfOutput': True, 'zeroConstraint': True}¶finalizeSampling()¶getCurrentVar()¶getFinalVar()¶getOutputs()¶getScaleFactor()¶get_accuracy(abs_error, rel_error, fv, tv, atol, rtol)¶get_true_value()¶linkToData(dataInput)¶parametersComments = {'duration': 'HRF length in seconds', 'hackCovarApost': 'Divide the term coming from the likelihood by the nb of voxels\n when computing the posterior covariance. The aim is to balance\n the contribution coming from the prior with that coming from the likelihood.\n Note: this hack is only taken into account when "singleHRf" is used for "prior_type"', 'normalise': 'If 1. : Normalise samples of Hrf, NRLs and Mixture Parameters when they are sampled.\nIf 0. : Normalise posterior means of Hrf, NRLs and Mixture Parameters when they are sampled.\nelse : Do not normalise.', 'priorType': 'Type of prior:\n - "singleHRF": one HRF modelled for the whole parcel ~N(0,v_h*R).\n - "voxelwiseIID": one HRF per voxel, all HRFs are iid ~N(0,v_h*R).', 'sampleFlag': 'Flag for the HRF estimation (True or False).\nIf set to False then the HRF is fixed to a canonical form.', 'zeroConstraint': 'If True: impose first and last value = 0.\nIf False: no constraint.'}¶parametersToShow = ['duration', 'zeroConstraint', 'sampleFlag', 'writeHrfOutput']¶reportCurrentVal()¶sampleNextAlt(variables)¶sampleNextInternal(variables)¶samplingWarmUp(variables)¶setFinalValue()¶updateNorm()¶updateObsersables()¶pyhrf.jde.jde_multi_sujets.HRF_Sampler(val_ini=None, do_sampling=True, use_true_value=False, duration=25.0, zero_contraint=True, normalise=1.0, deriv_order=2, covar_hack=False, prior_type='voxelwiseIID', regularise=True, only_hrf_subj=False, compute_ah_online=False)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
HRF sampler for multi subject model
calcXh(hrfs)¶checkAndSetInitValue(variables)¶computeStDS_StDY(rb_allSubj, nrls_allSubj, aa_allSubj)¶computeStDS_StDY_one_subject(rb, nrls, aa, subj)¶finalizeSampling()¶getCurrentVar()¶getFinalVar()¶getOutputs()¶getScaleFactor()¶get_accuracy(abs_error, rel_error, fv, tv, atol, rtol)¶get_true_value()¶initObservables()¶linkToData(dataInput)¶parametersComments = {'covar_hack': 'Divide the term coming from the likelihood by the nb of voxels\n when computing the posterior covariance. The aim is to balance\n the contribution coming from the prior with that coming from the likelihood.\n Note: this hack is only taken into account when "singleHRf" is used for "prior_type"', 'do_sampling': 'Flag for the HRF estimation (True or False).\nIf set to False then the HRF is fixed to a canonical form.', 'duration': 'HRF length in seconds', 'normalise': 'If 1. : Normalise samples of Hrf, NRLs andMixture Parameters when they are sampled.\nIf 0. : Normalise posterior means of Hrf, NRLs and Mixture Parameters when they are sampled.\nelse : Do not normalise.', 'prior_type': 'Type of prior:\n - "singleHRF": one HRF modelled for the whole parcel ~N(0,v_h*R).\n - "voxelwiseIID": one HRF per voxel, all HRFs are iid ~N(0,v_h*R).', 'zero_contraint': 'If True: impose first and last value = 0.\nIf False: no constraint.'}¶reportCurrentVal()¶sampleNextAlt(variables)¶sampleNextInternal(variables)¶samplingWarmUp(variables)¶setFinalValue()¶updateNorm()¶updateObsersables()¶updateXh()¶pyhrf.jde.jde_multi_sujets.LabelSampler(val_ini=None, do_sampling=True, use_true_value=False)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
CLASSES = array([0, 1])¶CLASS_NAMES = ['inactiv', 'activ']¶FALSE_NEG = 3¶FALSE_POS = 2¶L_CA = 1¶L_CI = 0¶checkAndSetInitValue(variables)¶compute_ext_field()¶countLabels()¶linkToData(dataInput)¶sampleNextInternal(v)¶samplingWarmUp(v)¶pyhrf.jde.jde_multi_sujets.MixtureParamsSampler(val_ini=None, do_sampling=True, use_true_value=False)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
I_MEAN_CA = 0¶I_VAR_CA = 1¶I_VAR_CI = 2¶L_CA = 1¶L_CI = 0¶NB_PARAMS = 3¶PARAMS_NAMES = ['Mean_Activ', 'Var_Activ', 'Var_Inactiv']¶checkAndSetInitValue(variables)¶computeWithJeffreyPriors(j, s, cardCIj, cardCAj)¶get_current_means()¶return array of shape (class, subject, condition)
get_current_vars()¶return array of shape (class, subject, condition)
get_true_values_from_simulation_cdefs(cdefs)¶linkToData(dataInput)¶sampleNextInternal(variables)¶pyhrf.jde.jde_multi_sujets.NRLs_Sampler(val_ini=None, do_sampling=True, use_true_value=False)¶Bases: pyhrf.xmlio.Initable, pyhrf.jde.samplerbase.GibbsSamplerVariable
checkAndSetInitValue(variables)¶computeAA()¶computeVarYTildeOpt(varXh, s)¶linkToData(dataInput)¶sampleNextInternal(variables)¶Define the behaviour of the variable at each sampling step when its sampling is not activated. Must be overriden in child classes.
samplingWarmUp(variables)¶pyhrf.jde.jde_multi_sujets.NoiseVariance_Drift_MultiSubj_Sampler(val_ini=None, do_sampling=True, use_true_value=False)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
checkAndSetInitValue(variables)¶linkToData(dataInput)¶sampleNextInternal(variables)¶pyhrf.jde.jde_multi_sujets.RHGroupSampler(val_ini=array([ 0.15]), do_sampling=True, use_true_value=False, prior_mean=0.001, prior_var=10.0)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
#TODO : comment
checkAndSetInitValue(variables)¶getOutputs()¶linkToData(dataInput)¶sampleNextInternal(variables)¶pyhrf.jde.jde_multi_sujets.Variance_GaussianNRL_Multi_Subj(val_ini=array([ 1.]), do_sampling=True, use_true_value=False)¶Bases: pyhrf.jde.samplerbase.GibbsSamplerVariable
checkAndSetInitValue(variables)¶linkToData(dataInput)¶sampleNextInternal(variables)¶pyhrf.jde.jde_multi_sujets.b()¶pyhrf.jde.jde_multi_sujets.create_gaussian_hrf_subject_and_group(hrf_group_base, hrf_group_var_base, hrf_subject_var_base, dt, alpha=0.0)¶pyhrf.jde.jde_multi_sujets.create_unnormed_gaussian_hrf_subject(unnormed_hrf_group, unnormed_var_subject_hrf, dt, alpha=0.0)¶Creation of hrf by subject. Use group level hrf and variance for each subject (var_subjects_hrfs must be a list) Simulated hrfs must be smooth enough: correlation between temporal coeffcients
pyhrf.jde.jde_multi_sujets.randn(d0, d1, ..., dn)¶Return a sample (or samples) from the “standard normal” distribution.
If positive, int_like or int-convertible arguments are provided,
randn generates an array of shape (d0, d1, ..., dn), filled
with random floats sampled from a univariate “normal” (Gaussian)
distribution of mean 0 and variance 1 (if any of the 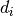 are
floats, they are first converted to integers by truncation). A single
float randomly sampled from the distribution is returned if no
argument is provided.
are
floats, they are first converted to integers by truncation). A single
float randomly sampled from the distribution is returned if no
argument is provided.
This is a convenience function. If you want an interface that takes a tuple as the first argument, use numpy.random.standard_normal instead.
| Parameters: | d1, .., dn (d0,) – The dimensions of the returned array, should be all positive. If no argument is given a single Python float is returned. |
|---|---|
| Returns: | Z – A (d0, d1, ..., dn)-shaped array of floating-point samples from
the standard normal distribution, or a single such float if
no parameters were supplied. |
| Return type: | ndarray or float |
See also
random.standard_normal()Notes
For random samples from 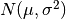 , use:
, use:
sigma * np.random.randn(...) + mu
Examples
>>> np.random.randn()
2.1923875335537315 #random
Two-by-four array of samples from N(3, 6.25):
>>> 2.5 * np.random.randn(2, 4) + 3
array([[-4.49401501, 4.00950034, -1.81814867, 7.29718677], #random
[ 0.39924804, 4.68456316, 4.99394529, 4.84057254]]) #random
pyhrf.jde.jde_multi_sujets.rescale_hrf_group(unnormed_primary_hrf, unnormed_hrf_group)¶pyhrf.jde.jde_multi_sujets.rescale_hrf_subj(unnormed_primary_hrf)¶pyhrf.jde.jde_multi_sujets.rescale_hrf_subj_var(unnormed_primary_hrf, unnormed_var_subject_hrf)¶pyhrf.jde.jde_multi_sujets.sampleHRF_single_hrf(stLambdaS, stLambdaY, varR, rh, nbColX, nbVox, hgroup)¶pyhrf.jde.jde_multi_sujets.sampleHRF_single_hrf_hack(stLambdaS, stLambdaY, varR, rh, nbColX, nbVox, hgroup)¶pyhrf.jde.jde_multi_sujets.sampleHRF_voxelwise_iid(stLambdaS, stLambdaY, varR, rh, nbColX, nbVox, hgroup, nbsubj)¶pyhrf.jde.jde_multi_sujets.simulate_single_subject(output_dir, cdefs, var_subject_hrf, labels, labels_vol, v_noise, drift_coeff_var, drift_amplitude, hrf_group_level, var_hrf_group, dt=0.6, dsf=4)¶pyhrf.jde.jde_multi_sujets.simulate_subjects(output_dir, snr_scenario='high_snr', spatial_size='tiny', hrf_group=None, nbSubj=10)¶Simulate daata for multiple subjects (5 subjects by default)