
Hierarchical Agglomerative Clustering
These routines perform some hierarchical agglomerative clustering of some input data. Currently, only Ward’s algorithm is implemented.
Authors : Vincent Michel, Bertrand Thirion, Alexandre Gramfort, Gael Varoquaux Modified: Aina Frau License: BSD 3 clause
pyhrf.sandbox.parcellation.FWHM(Y)¶pyhrf.sandbox.parcellation.GLM_method(name, data0, ncond, dt=0.5, time_length=25.0, ndelays=0)¶pyhrf.sandbox.parcellation.Memory(*args, **kwargs)¶pyhrf.sandbox.parcellation.Ward(n_clusters=2, memory=None, connectivity=None, copy=True, n_components=None, compute_full_tree='auto', dist_type='uward', cov_type='spherical', save_history=False)¶Bases: pyhrf.sandbox.parcellation.BaseEstimator, pyhrf.sandbox.parcellation.ClusterMixin
Ward hierarchical clustering: constructs a tree and cuts it.
| Parameters: |
|
|---|
children_¶array-like, shape = [n_nodes, 2] – List of the children of each nodes. Leaves of the tree do not appear.
labels_¶array [n_samples] – cluster labels for each point
n_leaves_¶int – Number of leaves in the hierarchical tree.
n_components_¶sparse matrix. – The estimated number of connected components in the graph.
fit(X, var=None, act=None, var_ini=None, act_ini=None)¶Fit the hierarchical clustering on the data
| Parameters: | X (array-like, shape = [n_samples, n_features]) – The samples a.k.a. observations. |
|---|---|
| Returns: | |
| Return type: | self |
pyhrf.sandbox.parcellation.WardAgglomeration(n_clusters=2, memory=None, connectivity=None, copy=True, n_components=None, compute_full_tree='auto', dist_type='uward', cov_type='spherical', save_history=False)¶Bases: pyhrf.sandbox.parcellation.AgglomerationTransform, pyhrf.sandbox.parcellation.Ward
Feature agglomeration based on Ward hierarchical clustering
| Parameters: |
|
|---|
children_¶array-like, shape = [n_nodes, 2] – List of the children of each nodes. Leaves of the tree do not appear.
labels_¶array [n_samples] – cluster labels for each point
n_leaves_¶int – Number of leaves in the hierarchical tree.
fit(X, y=None, **params)¶Fit the hierarchical clustering on the data
| Parameters: | X (array-like, shape = [n_samples, n_features]) – The data |
|---|---|
| Returns: | |
| Return type: | self |
pyhrf.sandbox.parcellation.align_parcellation(p1, p2, mask=None)¶Align two parcellation p1 and p2 as the minimum number of positions to remove in order to obtain equal partitions. :returns: (p2 aligned to p1)
pyhrf.sandbox.parcellation.assert_parcellation_equal(p1, p2, mask=None, tol=0, tol_pos=None)¶pyhrf.sandbox.parcellation.calculate_uncertainty(dm, g)¶pyhrf.sandbox.parcellation.compute_fwhm(F, dt, a=0)¶pyhrf.sandbox.parcellation.compute_hrf(method, my_glm, can, ndelays, i)¶pyhrf.sandbox.parcellation.compute_mixt_dist(features, alphas, coord_row, coord_col, cluster_masks, moments, cov_type, res)¶Within one given territory: bi-Gaussian mixture model with known posterior weights:
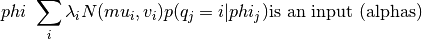
Estimation:
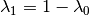 is the mean of posterior weights.
is the mean of posterior weights. 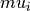 is estimated by weighted sample
mean and
is estimated by weighted sample
mean and 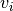 is estimated by weighted sample variance.
is estimated by weighted sample variance.
| Parameters: |
|
|---|
pyhrf.sandbox.parcellation.compute_mixt_dist_skgmm(features, alphas, coord_row, coord_col, cluster_masks, moments, cov_type, res)¶pyhrf.sandbox.parcellation.compute_uward_dist(m_1, m_2, coord_row, coord_col, variance, actlev, res)¶Function computing Ward distance: inertia = !!!!0
| Parameters: |
|
|---|---|
| Returns: |
|
pyhrf.sandbox.parcellation.compute_uward_dist2(m_1, features, alphas, coord_row, coord_col, cluster_masks, res)¶Function computing Ward distance: In this case we are using the model-based definition to compute the inertia
| Parameters: |
|
|---|---|
| Returns: |
|
pyhrf.sandbox.parcellation.feature_extraction(fmri_data, method, dt=0.5, time_length=25.0, ncond=1)¶fmri_data (pyhrf.core.FmriData): single ROI fMRI data
pyhrf.sandbox.parcellation.generate_features(parcellation, act_labels, feat_levels, noise_var=0.0)¶Generate noisy features with different levels across positions depending on parcellation and activation clusters.
| Parameters: |
|
|---|---|
| Returns: | The simulated the features. |
| Return type: | np.array((n_positions, n_features), float) |
pyhrf.sandbox.parcellation.hc_get_heads(parents, copy=True)¶Return the heads of the forest, as defined by parents :param parents: :type parents: array of integers :param The parent structure defining the forest (ensemble of trees): :param copy: :type copy: boolean :param If copy is False, the input ‘parents’ array is modified inplace:
| Returns: |
|
|---|
pyhrf.sandbox.parcellation.hrf_canonical_derivatives(tr, oversampling=2.0, time_length=25.0)¶pyhrf.sandbox.parcellation.informedGMM(features, alphas)¶Given a set of features, parameters (mu, v, lambda), and alphas: updates the parameters WARNING: only works for nb features = 1
pyhrf.sandbox.parcellation.informedGMM_MV(fm, am, cov_type='spherical')¶Given a set of multivariate features, parameters (mu, v, lambda), and alphas: fit a GMM where posterior weights are known (alphas)
pyhrf.sandbox.parcellation.loglikelihood_computation(fm, mu0, v0, mu1, v1, a)¶pyhrf.sandbox.parcellation.mixtp_to_str(mp)¶pyhrf.sandbox.parcellation.norm2_bc(a, b)¶broadcast the computation of ||a-b||^2 where size(a) = (m,n), size(b) = n
pyhrf.sandbox.parcellation.parcellation_hemodynamics(fmri_data, feature_extraction_method, parcellation_method, nb_clusters)¶Perform a hemodynamic-driven parcellation on masked fMRI data
| Parameters: |
|
|---|---|
| Returns: | parcellation array (numpy array of integers) with flatten spatial axes |
Examples #TODO
pyhrf.sandbox.parcellation.render_ward_tree(tree, fig_fn, leave_colors=None)¶pyhrf.sandbox.parcellation.represent_features(features, labels, ampl, territories, t, fn)¶Generate chart with features represented.
| Parameters: |
|
|---|---|
| Returns: |
|
| Return type: | features represented in 2D |
pyhrf.sandbox.parcellation.spatial_ward(features, graph, nb_clusters=0)¶pyhrf.sandbox.parcellation.spatial_ward_sk(features, graph, nb_clusters=0)¶pyhrf.sandbox.parcellation.spatial_ward_with_uncertainty(features, graph, variance, activation, var_ini=None, act_ini=None, nb_clusters=0, dist_type='uward', cov_type='spherical', save_history=False)¶Parcellation the given features with the spatial Ward algorithm, taking into account uncertainty on features (variance) and activation level:
| Parameters: |
|
|---|
pyhrf.sandbox.parcellation.squared_error(n, m)¶pyhrf.sandbox.parcellation.ward_tree(X, connectivity=None, n_components=None, copy=True, n_clusters=None, var=None, act=None, var_ini=None, act_ini=None, dist_type='uward', cov_type='spherical', save_history=False)¶Ward clustering based on a Feature matrix.
The inertia matrix uses a Heapq-based representation.
This is the structured version, that takes into account a some topological structure between samples.
| Parameters: |
|
|---|---|
| Returns: |
|
pyhrf.sandbox.parcellation.ward_tree_save(tree, output_dir, mask)¶